Ce que vous voyez est appelé un BOM (pour Byte Order Mark ou, en français, Marque d'ordre des octets). On le trouve au début des fichiers enregistrés en unicode (UTF-8, UTF-16 ou UTF-32), il contient des renseignements sur le sens de lecture des données.
Ennuis possibles
Malheureusement, certains logiciels n'interprètent pas correctement le BOM, ils le considèrent comme une partie du texte et l'affichent. Il en résulte alors ces fameux caractères: ; Lesquels peuvent se révéler problématiques sur la toile, provoquant notamment l'envoi prématuré des en-têtes, la corruption du rendu sous Internet Explorer ou encore des espaces indésirables.
Pour une page en ligne il est possible de vérifier la présence de BOM grâce à cet outil proposé par Richard Ishida.
Inutile en UTF-8
L'encodage UTF-8, contrairement à ses grands frères, ne possède qu'un seul sens de lecture des données. En conséquence l'information fournie par le BOM n'y est pas indispensable et on peut donc le retirer; ce qui est vivement recommandé, au moins pour tout ce qui touche à internet car il s'agit de l'encodage désormais privilégié pour le web.
Enlever le BOM
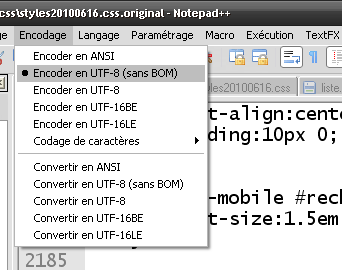
Pour retirer le BOM il faut configurer votre éditeur de texte préféré de manière à ce qu'il ne l'ajoute pas lors de l'enregistrement. La quasi totalité des programmes le permet, cependant l'option est souvent difficile à trouver. Pour vous aider, sachez que les désignations suivantes sont parfois utilisées à la place de BOM: marque d'ordre des octets, octets de signatures, signature UTF-8, ordre UTF-8, cookie UTF-8. Pour ceux qui utilisent Windows, vous pouvez également vous servir de kaboom.